发票OCR

由于老婆是会计,她们需要发票电子化管理以及自动验真,发票多了之后需要对发票进行灵活查询和品目分类统计等,所以空闲之余使用GO+python开发一个发票电子管理系统。
Step-1:paddle0cr服务安装
1.conda创建python-3.7版本
2.安装paddle:python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
3.安装paddle-ocr:
pip install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple
4.发布ocr-restapi服务:
PaddleHub Serving可用CPU进行发布,
pip3 install paddlehub==2.1.0 --upgrade -i https://mirror.baidu.com/pypi/simple
在gitee上下载paddleocr的代码
进入paddleocr/deploy目录:
hub install deploy/hubserving/ocr_system/
安装过程遇到报错,通过执行以下命令修复:
yum install gcc-c++
pip intall lanms-neo
pip install Polygon3
在paddleocr-gitee上下载对应模型,生成inference文件夹,并把inference放到和deploy目录并行,最后执行启动命令发布rest服务:
hub serving start -m ocr_system
Step-2:centos-xpdf安装
安装xpdf,用于PDF转图片,且支持中文。
Download Xpdf and XpdfReader
根据操作系统下载Xpdf command line tools,linux上主要是字体各种缺失,
重点注意:xpdf当前目录执行转换正常,无缺失字体报错,但把xpdf配置在/etc/profile作为环境变量,在执行转换时就报字体缺失,感觉xpdfrc配置文件失效。最终在执行pnftopng时加上-cfg /usr/local/bin/xpdf/xpdfrc正常,完整执行命令如下:
pdftopnf -cfg /usr/local/bin/xpdf/xpdfrc -f 1 -l 1 /root/test.pdf /root/test
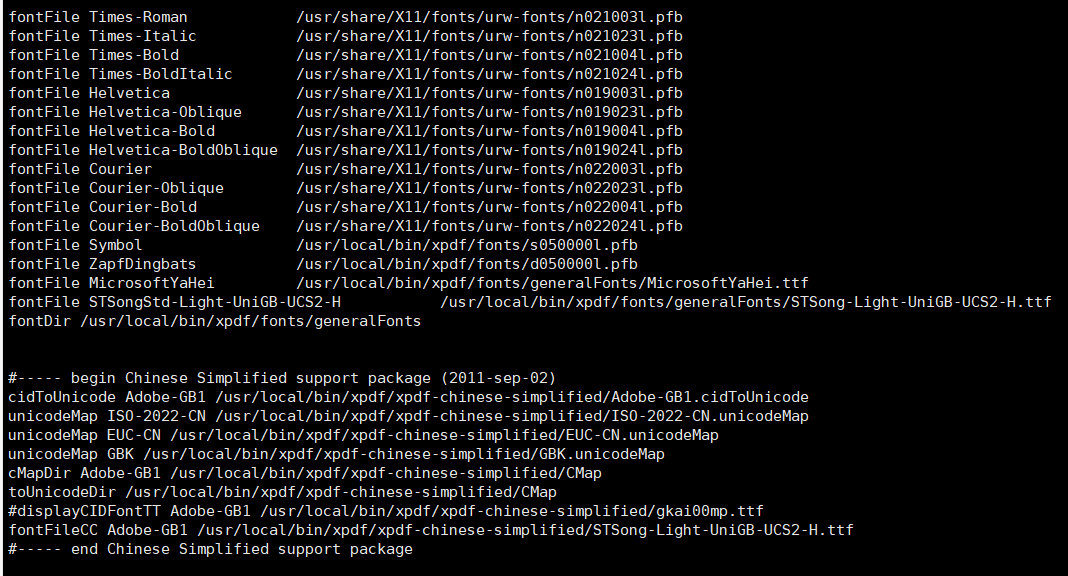
xpdfrc文件最关键,定义了字体路径,不同系统版本的字体路径不一样,根据自己机器修改,配置如下。使用过程中如果报错,根据报错提示的缺失字体,可执行下载,放到xpdf/fonts/generalFonts目录。
参考:http://www.taodudu.cc/news/show-4148359.html?action=onClick
Step-3:centos-zbar服务安装
zbar用于识别图片中二维码
centos安装zbar
yum install zbar-devel
zbarimg **.png
Step-4:发票验真
发票验真平台有极其变态的验证码,前期尝试用OCR模型识别,但是精度很差,如果要采集平台验证码,在做标记训练,太花时间,最后找到一个验真接口,免费但是有调用限制,土豪可以调用华为云-云市场的验真接口